TECNOLOGIA: SONANTIC LEGGE RECITANDO CIÒ CHE SCRIVI, INSERENDO TONALITÀ UMANE
La qualità delle voci generate dall'intelligenza artificiale è migliorata rapidamente negli ultimi anni, ma ci sono ancora aspetti del linguaggio umano che sfuggono all'imitazione sintetica. Certo, gli attori dell'IA possono fornire voci fuori campo aziendali fluide per presentazioni e pubblicità, ma performance più complesse, ad esempio una resa convincente di Amleto, rimangono fuori portata.
Sonantic, una startup vocale AI, afferma di aver fatto un piccolo passo avanti nello sviluppo di deepfake audio, creando una voce sintetica in grado di esprimere sottigliezze come prese in giro e flirt. La società afferma che la chiave del suo progresso è l'incorporazione di suoni non vocali nel suo audio; addestrando i suoi modelli di intelligenza artificiale a ricreare quelle piccole prese di respiro - minuscoli scherni e risatine semi-nascoste - che conferiscono al linguaggio reale il suo marchio di autenticità biologica.
“LE EMOZIONI PIÙ GRANDI SONO UN PO' PIÙ FACILE DA CATTURARE”
"Abbiamo scelto l'amore come tema generale", ha detto a The Verge il co-fondatore e CTO di Sonantic John Flynn. “Ma il nostro obiettivo di ricerca era vedere se potessimo modellare emozioni sottili. Le emozioni più grandi sono un po' più facili da catturare".
Nel video qui sotto, puoi ascoltare il tentativo dell'azienda di un'IA civettuola, anche se pensi che catturi o meno le sfumature del linguaggio umano è una domanda soggettiva. Al primo ascolto, ho pensato che la voce fosse quasi indistinguibile da quella di una persona reale, ma i colleghi di The Verge affermano di averla rilevata istantaneamente come un robot, indicando gli spazi inquietanti lasciati tra alcune parole e una leggera increspatura sintetica in la pronuncia.
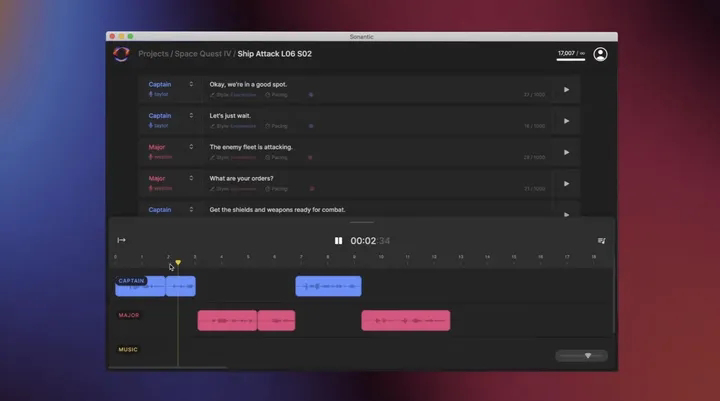
Zeena Qureshi, CEO di Sonantic, descrive il software dell'azienda come "Photoshop for voice". La sua interfaccia consente agli utenti di digitare il discorso che vogliono sintetizzare, specificare l'atmosfera della consegna e quindi selezionare da un cast di voci AI, la maggior parte delle quali sono copiate da veri attori umani. Questa non è affatto un'offerta unica (rivali come Descript vendono pacchetti simili), ma Sonantic afferma che il suo livello di personalizzazione è più approfondito di quello dei rivali.
Le scelte emotive per la consegna includono rabbia, paura, tristezza, felicità e gioia e, con l'aggiornamento di questa settimana, civettuola, timida, presa in giro e vanagloria. Una "modalità regista" consente ancora più modifiche: l'intonazione di una voce può essere regolata, l'intensità della consegna aumentata o diminuita e quelle piccole vocalizzazioni non vocali come risate e respiri inseriti.
"Penso che questa sia la differenza principale: la nostra capacità di dirigere, controllare, modificare e scolpire una performance", afferma Flynn. “I nostri clienti sono principalmente studi di gioco tripla A, studi di intrattenimento e ci stiamo espandendo in altri settori. Di recente abbiamo stretto una partnership con Mercedes [per personalizzare il suo assistente digitale in auto] all'inizio di quest'anno".
Come spesso accade con tale tecnologia, tuttavia, il vero punto di riferimento per i risultati di Sonantic è l'audio che esce fresco dai suoi modelli di apprendimento automatico, piuttosto che quello utilizzato nelle demo raffinate e pronte per le PR. Flynn afferma che il discorso sintetizzato per il suo video civettuolo richiedeva "pochissime regolazioni manuali", ma l'azienda ha eseguito ciclicamente alcuni rendering diversi per trovare l'output migliore.
Per cercare di ottenere un campione grezzo e rappresentativo della tecnologia di Sonantic, ho chiesto loro di rendere la stessa linea (diretta a te, caro lettore di Verge) usando una manciata di stati d'animo diversi. Puoi ascoltarli tu stesso per confrontarli da questo articolo.
- Eyes Bio
Articolo pubblicato anche su: The Verge


Commenti
Posta un commento